
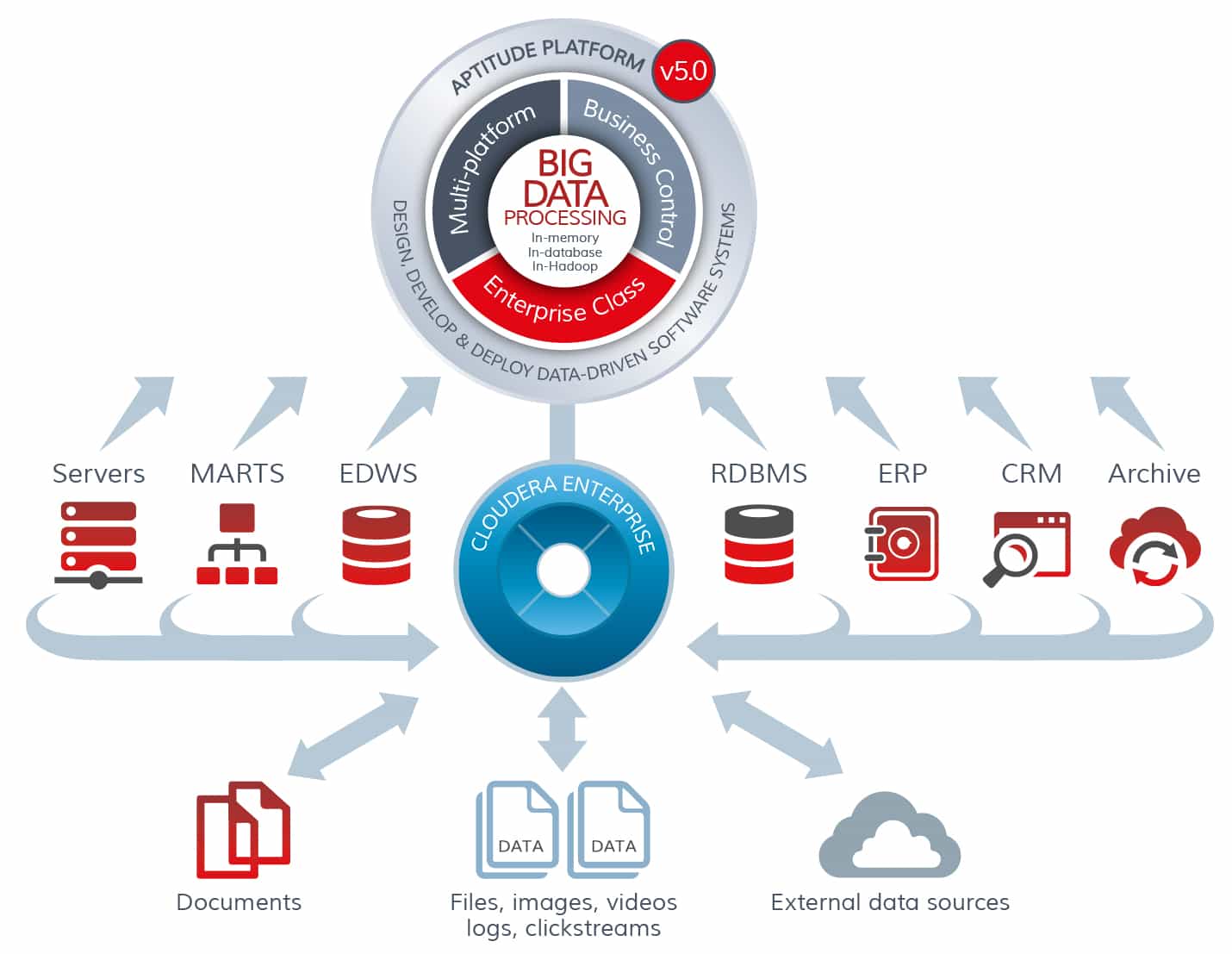
The Aptitude platform has always excelled at rapidly processing massive datasets using in-memory and in-database processing. The support for in-Hadoop processing in version 5 will empower enterprises to take advantage of this latest technology alongside their existing big data infrastructure.
Aptitude Version 5 Feature Summary
- Support for Hadoop Distributed File System (HDFS) including HDFS Browser and an Aptitude HDFS Device
- Kerberos Security Support on Aptitude devices
- Apache Pig and the ability to deploy Pig Latin Scripts
- New Impala Interface
- Improvements to Hive interface
- Informix Support through ODBC
- Teradata 15 Support including improved support of Teradata Parallel Transporter (TPT)
- Oracle 12C Support
Complete tooling for Apache Hadoop – Hive, HDFS, Impala and PigLatin
Aptitude version 5 introduces broad support for Hadoop, including graphical Hive and Impala interfaces, HDFS devices, and support for Pig Latin.
Hive & HDFS
The graphical Hive interface (introduced first in Aptitude version 4.2) is used to deploy SQL-like statements to Hadoop clusters. This builds on Aptitude’s DBClarity module which is used to deploy in-database logic via drag-and-drop of graphical diagrams. Users can even reverse engineer existing HiveQL code into Aptitude’s graphical diagrams! This makes it easier for enterprise teams to map and explain application logic to less-technical teams.
Version 5 offers a new Aptitude HDFS device and browser. Aptitude uses a plug and play device architecture to allow a wide range of technologies and data sources to be quickly (and repeatedly) integrated into enterprise applications.
Impala
Aptitude’s new Impala interface enables customers to run real-time queries against Hadoop, perfect for retrieving smaller amounts of data or running an analytical query. We see this as being complementary to Hive, which is more suited to large batch-style processes, allowing our customers to combine both technologies in a single application and leverage the most appropriate technology for the job in hand.
Pig Latin
Finally, Aptitude version 5 provides support for Pig Latin to allow users to focus more on using the power of Hadoop for processing large and disparate data sets while spending less time writing map reduce programs. Of course these Pig Latin scripts, along with all other Aptitude capabilities, can be seamlessly incorporated into Aptitude business processes to provide control, transparency and auditability across the big data ecosystem.
Increased multi-platform support
We know that Enterprise Architects and CTOs need approaches and tools to drive value and ROI from existing infrastructure. To this end, Aptitude Software partners with Teradata, IBM (Netezza), Cloudera, Oracle and SAP to ensure that users can access and process their data in the right places. Version 5 increases the multi-platform capabilities with Informix through ODBC, Teradata TPT support and Oracle 12C.
For the latest information on the Aptitude Platform see our resources page.
